Today is a great day: with the announcement of Eclipse Mars, many great projects are released, and Sirius 3.0 is part of this release train.
When I have a look at the status of the Sirius project today, one soundtrack immediately comes to mind: Harder, Better, Faster, Stronger

Work on it harder
One first fact, looking at the project’s statistics, is that the Sirius team worked hard on this release to deliver some new cool features and improve the existing ones:
| Version | Date | Total Closed | Feature Requests |
|---|---|---|---|
| 1.0.0(Luna) | June 14 | 100 | 2 |
| 1.0.1 | Aug 14 | 20 | - |
| 2.0.0 | Oct 14 | 113 | 27 |
| 2.0.1 | Nov 14 | 2 | - |
| 2.0.2 | Dec 14 | 15 | - |
| 2.0.3 | Jan 15 | 16 | - |
| 2.0.4 | Feb 15 | 8 | - |
| 2.0.5 | Apr 15 | 8 | - |
| 3.0.0(Mars) | Jun 15 | 213 | 35 |
| 426 | 64 |
This release is the first one on which the team worked at full speed, so for the future you can expect the same amount of work done.
Make it better
Their goal was to provide a better tooling for the end users by improving the diagram user experience. This work started with Sirius 2.0 and some of the following features are there since then.
Resizing a container
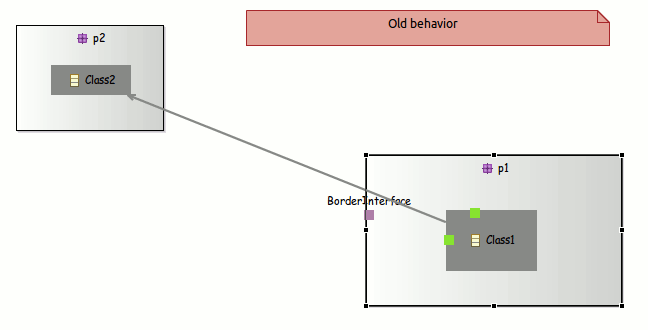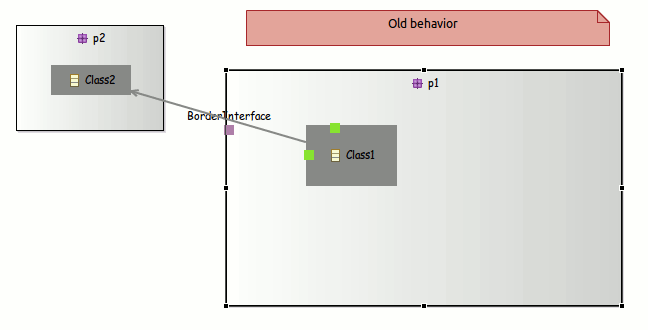
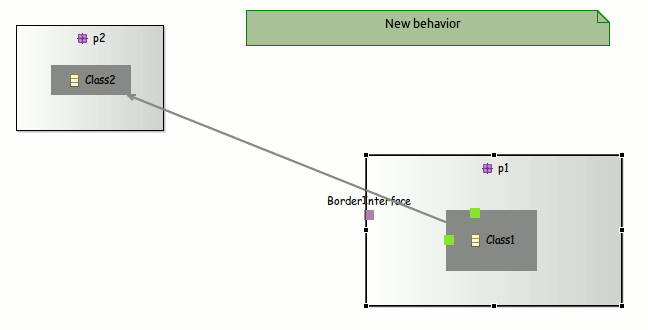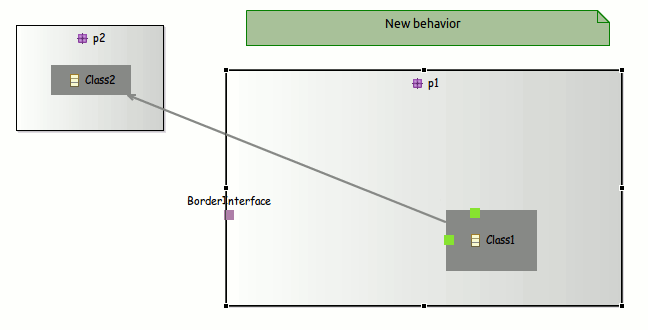
Positioning elements
| Snap To Shape enabled by default for new diagrams | 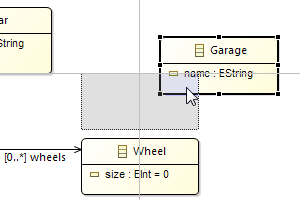 |
| Snap To Grid now used when an element is created | 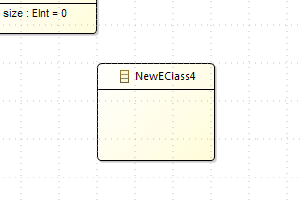 |
| Resize no longer change ports or children’s location | 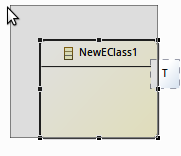 |
| Actions to distribute shapes | 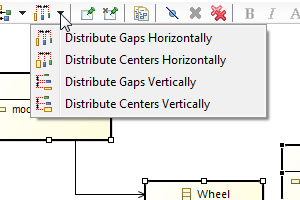 |
| Action to reset the diagram origin |  |
Edges layouting
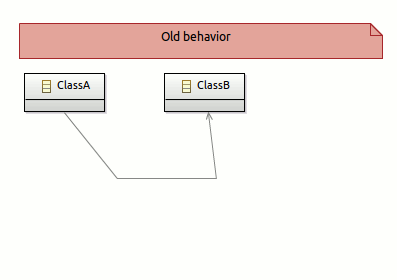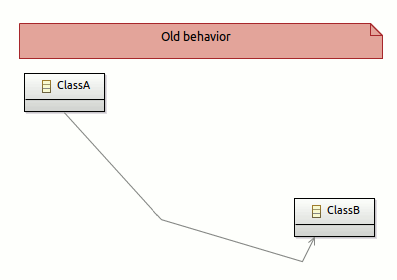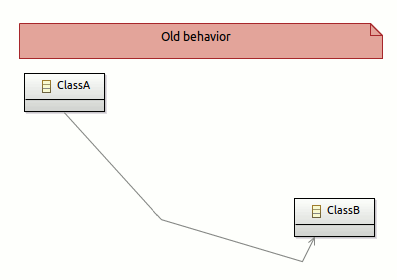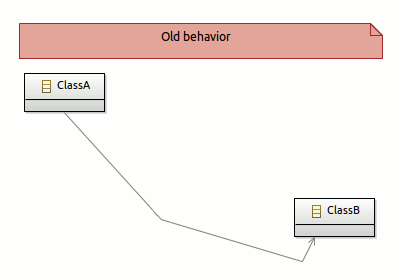
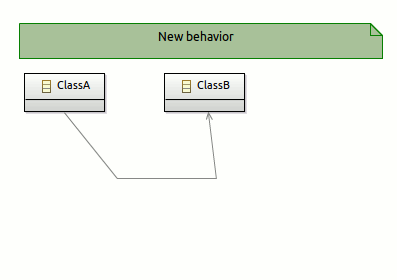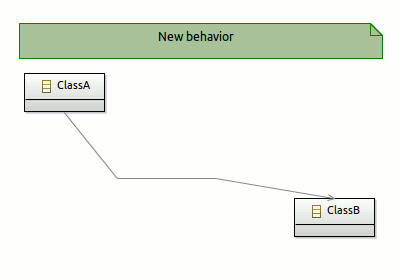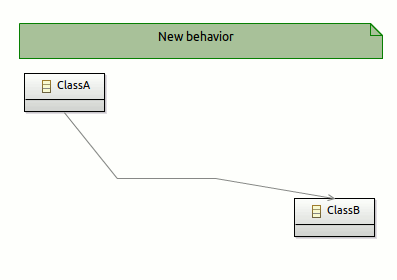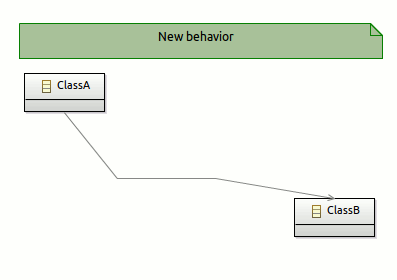
Beautiful editor
The editor was also improved to provide:
- Anchor on borders: Now the edges are linked closely to the images, you just need to define images with an transparent background.
- Underlined and strike through style for labels
- Compartments: There are two new values available for a container mapping
Vertical StackandHorizontal Stack. This means that the defined container will show its children as a vertical/horizontal stack of compartments. Thanks to this new feature, you are able to define a dynamic number of compartments.
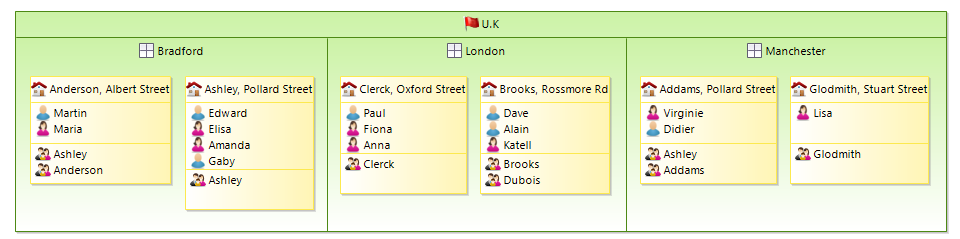
Compartments are just a specific setting of a full blown container mapping making it easy to create any artificial level of compartments independently from the metamodel structure.
Have a look at the Sirius compartments documentation for more details.
Do it faster
The goal was to get a runtime which react well with 1 million elements. Why one million? Because it is a beautiful number… but also because we noted that the modeling projects are fastly growing to 200K elements and 500K in case of in-depth analysis. Usually when you are over 500K, it means it’s time to re-think the process as you will likely need to decouple models with a clear and defined life-cycle. That is why we aim Sirius to work with 1 millions, then it will be really smoothly with the more usual 500K use case.
Sirius performances are in constant improvements, and this version comes with significant enhancements on heap consumption and time execution.
| Time (sec) | Heap (Mb) | Time Variation | Heap Variation | |
|---|---|---|---|---|
| Open Huge Project | 80 | 276 | -31,00% | -20,00% |
| Open Big Class Diagram | 11 | 24 | -54,00% | +20,00% |
| Refresh Big Class Diagram | 0,731 | 0 | -18,00% | 0,00% |
| Save After Diagram Change | 26 | 0 | -23,00% | 0,00% |
| Close Diagram | 0,1 | -6 | 0,00% | 0,00% |
| Close Project | 55 | 294 | 0,00% | 0,00% |
On big operations, the model footprint is reduced by 20%. To do so, major work was done on:
- using MinimalEObject
- Transforming Colors from full-blown EObject into Immutable DataType
- Detecting and fixing leaks
- Reducing the usage of adapters.
Then the save strategy was reviewed as well as the diagram refresh and the image cache.
Another big task was to reduce the latency. First, on the UI runtime:
- model element selection dialogs must be used for big models.
- the right-click in the explorer was optimized.
- and the property views made with EEF are better integrated.
And then to reduce the latency on tables, SWT refreshes are now done in batch and the team also improved the table model refresh.
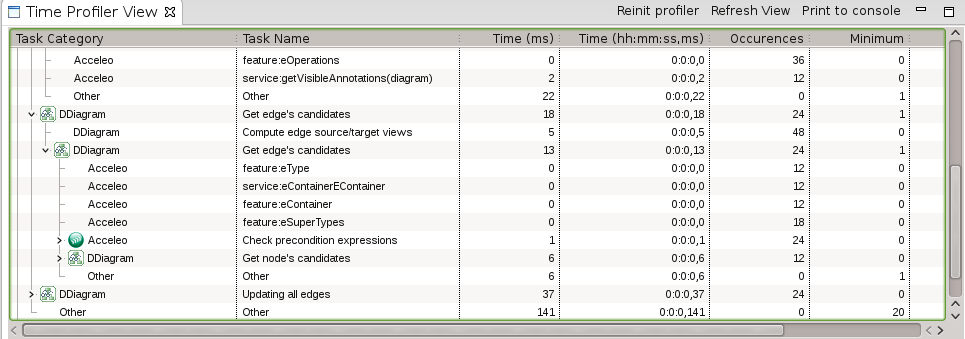
Performance is also your matter! It really depends on your .odesign specification. You should focus on queries which will have a complexity depending on the size of the model: measure, improve and repeat! Think about using the Sirius embedded profiler:
Make us stronger
Definition tooling
The Sirius team also worked to polish the specifier editor. They improved many different small things which will really enhance the specifier work as it will guarantee a better odesign validation and an efficient navigation.
- Workspace class loading is BACK: With Sirius 3 you can define Java services and then try them directly in your current development environment, you do not need anymore to launch another runtime just to test your services!
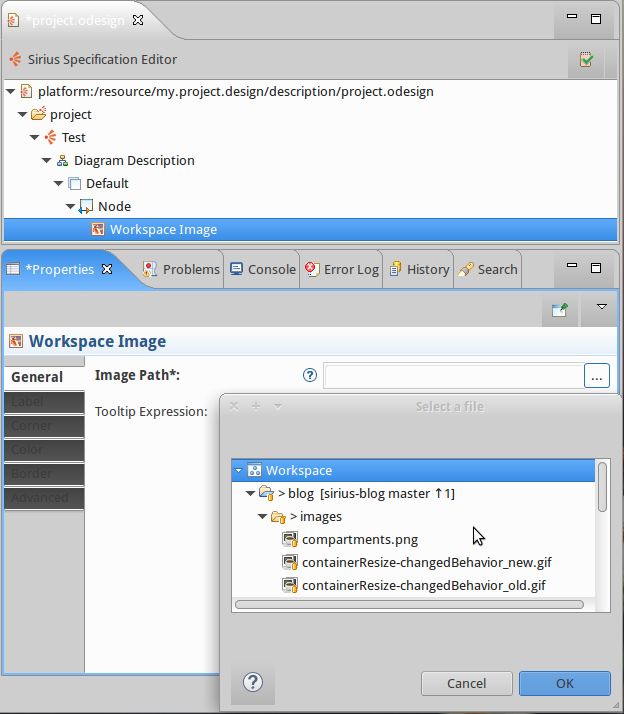
- Image path validation and selection wizard: Now, there is a selection wizard to choose an image and then validation exists on image path. You will never get a not found image.

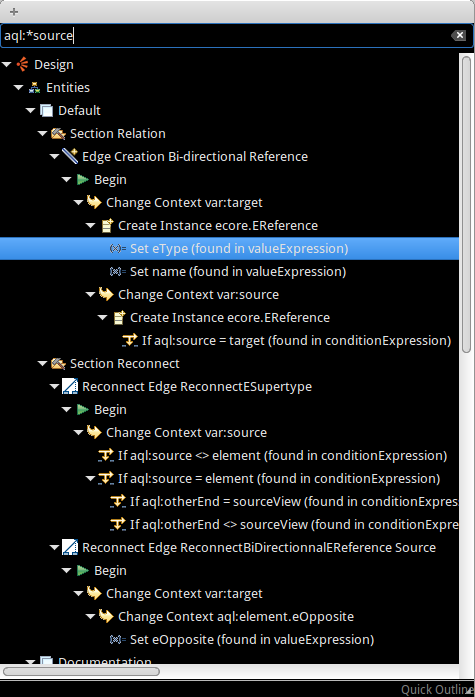
- Quick Outline: An awesome improvement: it allows to quickly find any element in a odesign! Just call
Ctrl+Oand a wizard shows up to help you searching through the viewpoint specification.
- Prioritized sub menus: Another great thing, the menus have been reordered and now the most used elements are available at the top.
Query languages
If you are used to work with Sirius, you already know that writing queries can turn to a severe headache due to the lack of detailed type information.
Actually, there are in Sirius 5 different interpreters to write your queries:
- Feature:
feature: - Service:
service: - Var:
var: - MTL:
[/] - and the legacy one:
<%%>
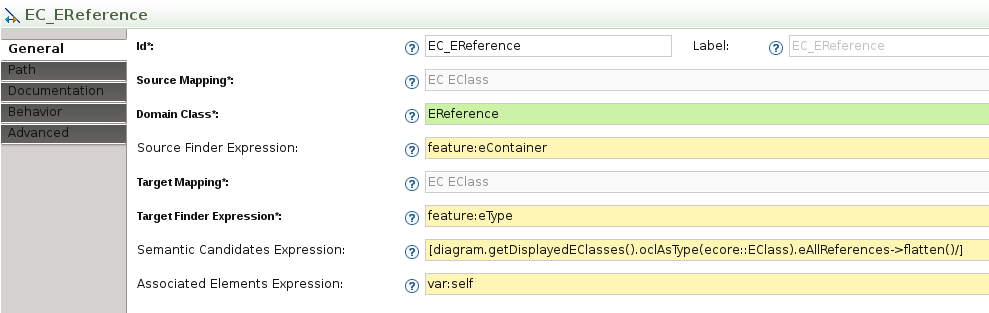
The .odesign specification is as flexible as possible, tools can be reused among mappings, mappings can be reused by other mappings, but that means one variable definition can actually have several types depending on the .odesign structure. If we have a look at the following query: What is the type of var:source?
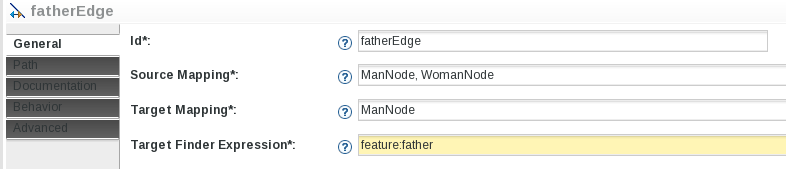
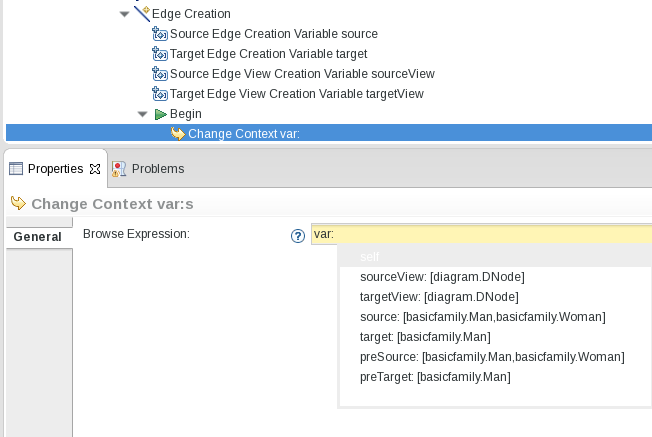
Regarding our example, source can be a Man or a Woman but it could be Woman or Package. Then the source variable can be of multiple types and those types may have no common ancestor other than EObject.
Type analysis within the action language requires a stronger type information from interpreters. It is implemented in feature:, var:. We made some improvements in [/] and there is simply no support in legacy <%%> and ocl:. What we want is a good reference support.
The Acceleo Query Language also known as AQL comes to our rescue. The implementation of AQL is specifically tailored for the Sirius use case. We have many variables for a given expression and null values are common. The usage is really interactive and so the context is constantly changing. I can hear you “Hoooo no, not yet another language…”. Don’t be afraid! You know OCL ? Then you know AQL.
The most important things to know is that:
- You will find the classic operations like
filter,collect, - And some convenient ones as:
eInverse(),eResource()… -
There is no implicit variable:
[name/]is invalid becomesself.name[self.eContents()->select(name.startsWith('A'))/]is invalid and becomesself.eContents()->select(i | i.name.startsWith('A')self.referenceWithNoValue.someOtherAttributehas no evaluation error, returns"Nothing"
AQL is not strictly compatible with MTL but a subset of MTL works for both.
We did some benchmarks with the different queries engines available in Sirius:
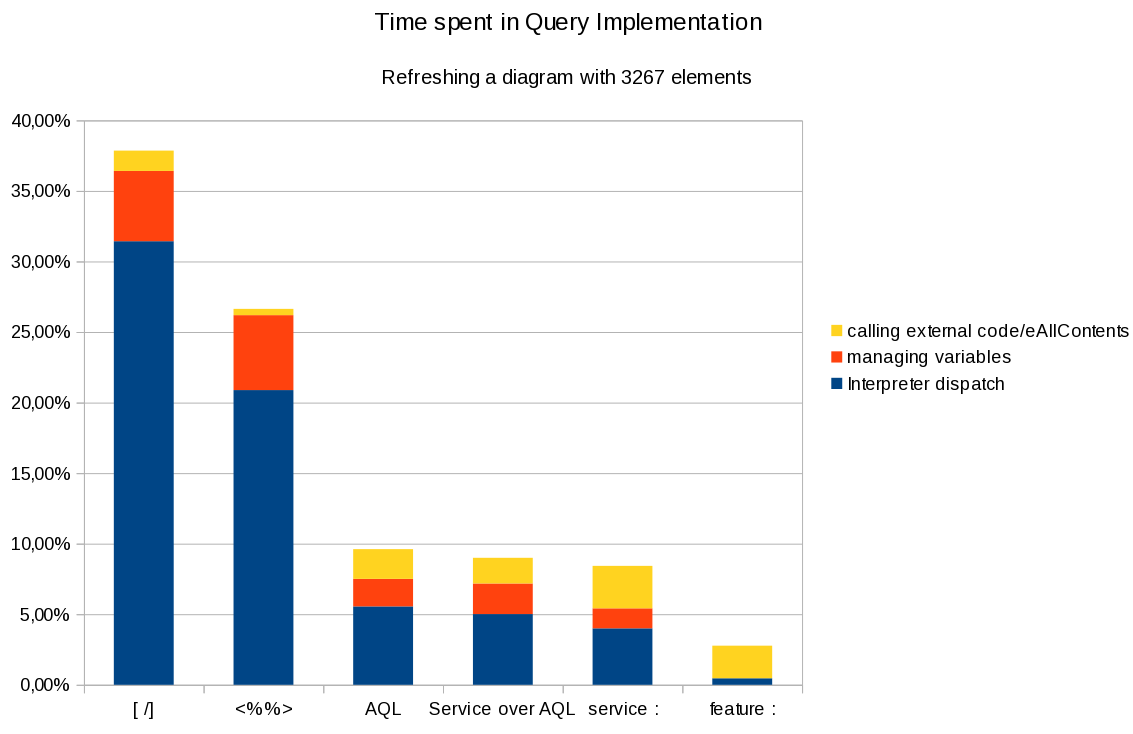
There is no good reason not to use it considering the overhead vs the flexibility and strong validation. In Sirius 3.0, it is delivered as an experimental feature but it will be available officially for the next 3.1 release.
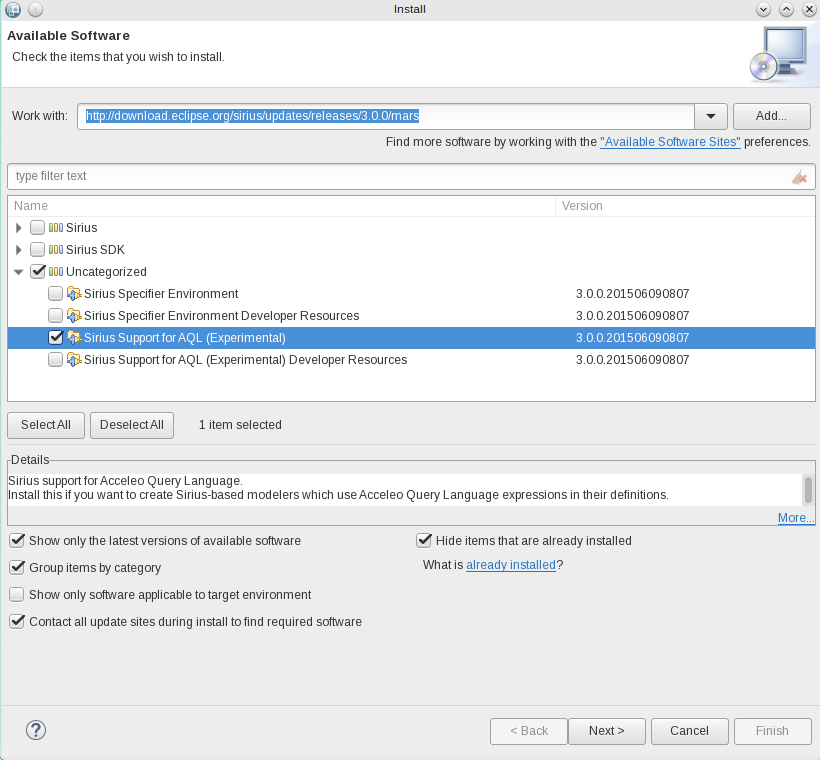
So consider using it from now on if you are still using Acceleo 2 expressions (<%%>). Otherwise, if you are using MTL ([/]), you can prepare your queries to make the migration easier.
To get more details about what is arriving in Sirius 3.0, have a look at the release notes and to the slides or the video of Cédric Brun EclipseCon France talk.
Even if Sirius 3.0 is major version, don’t be afraid! The models are automatically migrated by Sirius, the API changes are well documented in the release notes and some projects such as EcoreTools or UML Designer could upgrade just by changing the version range in the plugin, no impact on the code.
The 3.1 version is planned for November and the next topics of work will be: more flexibility for diagram UX, compartments feature complete, bullet-proof AQL and again more performance and scalability improvements… and your priority is our priority for the future. So don’t be shy, report what you need and want on the bugzilla and remember you can sponsor us to get it done quickly!
Let’s have Daft Punk conclude this post:
More than ever
Hour after
Our work is
Never over